这个项目是一个公众号文章爬取项目,目的是提供一个本地的公众号文章收藏和浏览工具,可以将线上的文章本地化,有利于快速查找和浏览,同时也可以防止好文章被删除,往后无法查看的问题。
而项目的爬取方式是基于一个知乎专栏的内容进行改写,该专栏使用的是python和django做后台服务,而这个项目是改用Java web的方式去做后台服务,而具体的实现方式和处理逻辑可以参照专栏,这里只给出这个项目的实现方式。
由于要做一个可供浏览阅读的界面,而浏览界面需要兼容多个系统,所以这个项目做成了BS架构,服务的技术架构如下:
- 后台框架:Spring+SpringMVC+Mybatis
- 数据库:MongoDB+Mysql
- 前端页面:bootstrap+velocity+angularjs
- 数据转发:anyproxy
项目里运用了两种不同的数据库,一个是关系型数据库Mysql,另一个是非关系型数据库MongoDB,用途如下:
- Mysql Mysql的作用是保存公众号和文章信息,项目中的表结构如下:
CREATE TABLE `tb_log` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`error` text NOT NULL COMMENT '错误信息',
`str` text COMMENT '参数str',
`url` text COMMENT '参数url',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=14 DEFAULT CHARSET=utf8;
CREATE TABLE `tb_post` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) NOT NULL COMMENT '文章对应的公众号biz',
`field_id` int(11) NOT NULL COMMENT '微信定义的一个id,每条文章唯一',
`title` varchar(255) NOT NULL DEFAULT '' COMMENT '文章标题',
`title_encode` text NOT NULL COMMENT '文章标题编码,防止文章标题出现emoji',
`digest` varchar(500) NOT NULL DEFAULT '' COMMENT '文章摘要',
`digest_encode` text NOT NULL COMMENT '文章摘要编码,防止文章摘要出现emoji',
`content_url` varchar(500) NOT NULL COMMENT '文章地址',
`source_url` varchar(500) NOT NULL COMMENT '阅读原文地址',
`cover` varchar(500) NOT NULL COMMENT '封面图片',
`is_multi` int(11) NOT NULL COMMENT '是否多图文',
`is_top` int(11) NOT NULL COMMENT '是否头条',
`datetime` int(11) NOT NULL COMMENT '文章时间戳',
`readNum` int(11) NOT NULL DEFAULT '1' COMMENT '文章阅读量',
`likeNum` int(11) NOT NULL DEFAULT '0' COMMENT '文章点赞量',
`is_exsist` int(11) NOT NULL DEFAULT '0' COMMENT '是否已爬取,0:未爬取,1:已爬取,2:文章不存在',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=72 DEFAULT CHARSET=utf8 COMMENT='公众号文章表|CreateBaseDomain\r\n公众号文章表';
CREATE TABLE `tb_tmplist` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`content_url` varchar(255) DEFAULT NULL COMMENT '文章地址',
`loading` int(11) DEFAULT '0' COMMENT '读取中标记',
PRIMARY KEY (`id`),
UNIQUE KEY `content_url` (`content_url`)
) ENGINE=InnoDB AUTO_INCREMENT=72 DEFAULT CHARSET=utf8 COMMENT='采集队列表|CreateBaseDomain\r\n采集队列表';
CREATE TABLE `tb_weixin` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`biz` varchar(255) DEFAULT '' COMMENT '公众号唯一标识biz',
`nickName` varchar(255) DEFAULT '' COMMENT '公众号昵称',
`avatar` varchar(500) DEFAULT '' COMMENT '公众号头像',
`collect` int(11) DEFAULT '1' COMMENT '记录采集时间的时间戳',
`status` int(2) DEFAULT '1' COMMENT '状态,0:软删除,1:启用',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8 COMMENT='公众号表|CreateBaseDomain\r\n公众号表';- MongoDB MongoDB的作用是保存文章的标题和内容,方便做后台文章搜索,表结构如下:
{
id: string,
content: string
}Anyproxy是一个抓包工具,用途是抓取公众号和文章的相关数据,并将数据转发到后台中。这实质上是利用了中间人攻击的原理,将微信客户端浏览公众号的页面信息转发到后台后,再返回到微信客户端中。
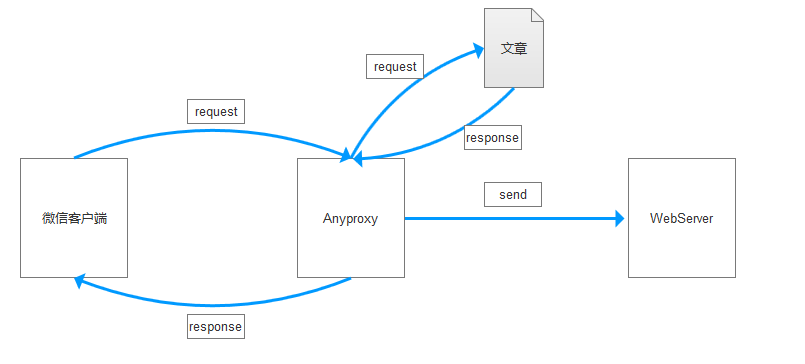
Anyproxy的相关信息和技术指南可查看这个链接:http://anyproxy.io
Anyproxy的转发功能是自行修改文件rule_default.js实现的,具体代码参考这个文件
本机web访问地址:http://localhost:8887/index
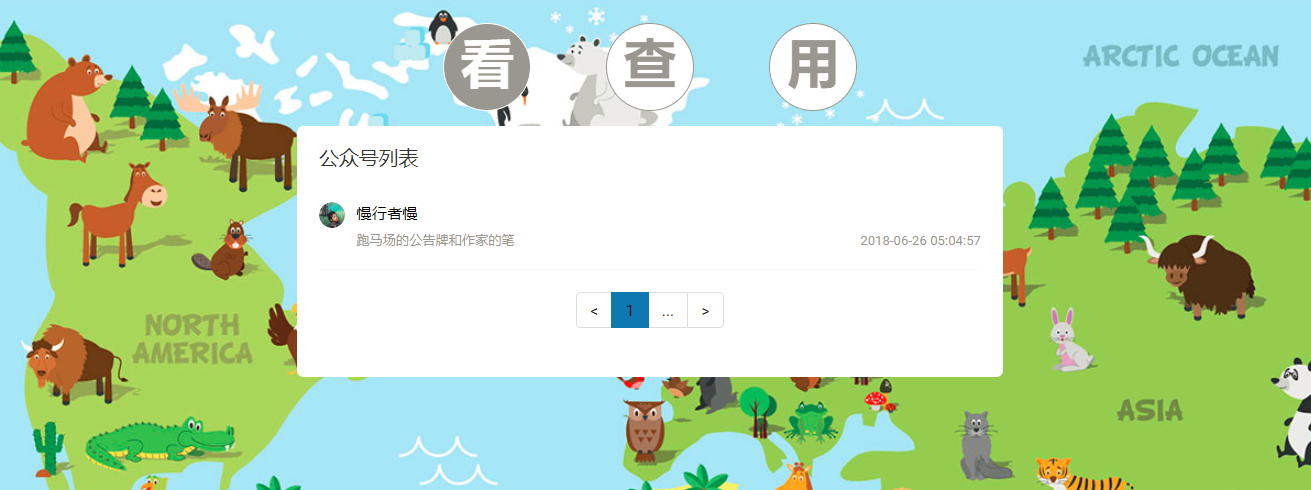
- 公众号列表查看
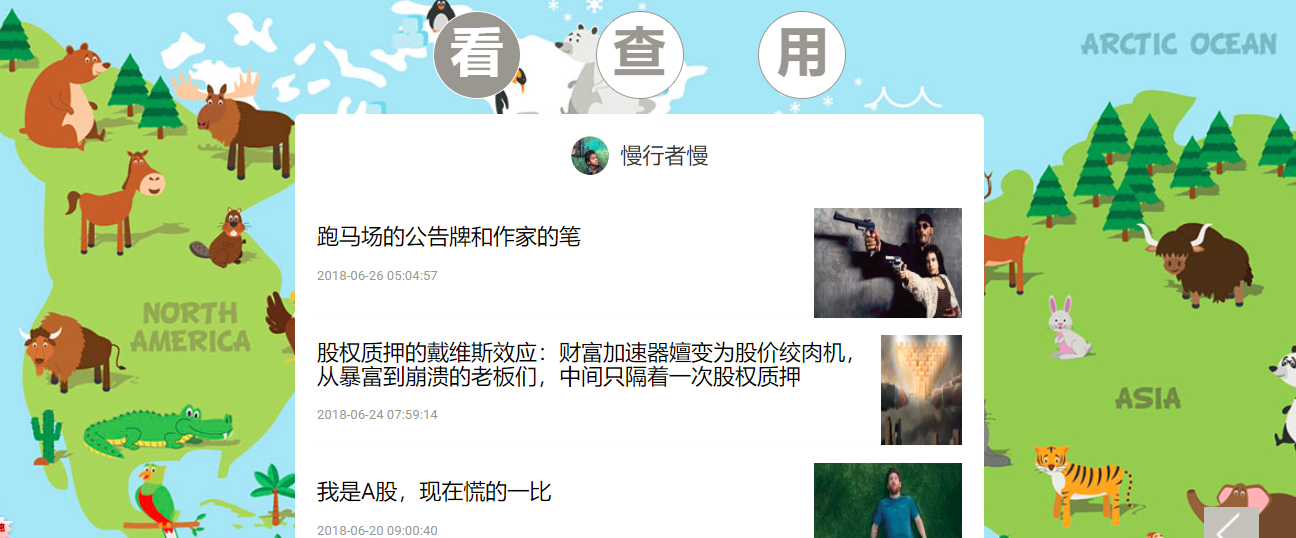
- 文章列表查看
- 文章查看

- 文章爬取
- 设置Anyproxy作为网络代理,其中需要安装https证书
- 安装微信客户端,并登录相关账号
- 点击打开要爬取的公众号
- 等待程序自动爬取文章数据
爬虫爬取的时候仅爬取文章中的主要内容,所以最后保存的html在代码上看是不完整的。文章中的图片也是直接保存到本地中的,所以在本地中是可以直接查看文章的完整内容(带音频的文章暂时没试过)。
文件保存的方式:
-
根目录:在
project.properties中做配置的 -
文件保存的路径:
/{weixinId}/{postId} -
文件的命名:html是以postId来命名的,图片是按原有的Id来命名的
文章内容是直接爬取公众号的内容到本地html中,而web服务是有浏览本地文件的功能,所以需要做本地文件的浏览,相关代码如下:
/**
* 浏览访问本地的图片
*/
@RequestMapping(value = "/avatar/{biz}/{avatar}" , method = RequestMethod.GET)
public void getAvatar(@PathVariable("biz") String biz, @PathVariable("avatar") String avatar, HttpServletResponse response) throws IOException {
byte[] bytes = Files.readAllBytes(Paths.get(postFilePath + "\\" + biz + "\\" + avatar));
response.setCharacterEncoding("UTF-8");
response.setContentType("image/*;charset=UTF-8");
OutputStream out = response.getOutputStream();
out.write(bytes);
out.close();
}/**
* 查看本地文章
*/
@RequestMapping(value = "/openPost/{biz}/{post}", method = RequestMethod.GET)
public ModelAndView openPost(@PathVariable("biz") String biz, @PathVariable("post") String post, HttpServletRequest request) throws IOException {
byte[] bytes = Files.readAllBytes(Paths.get(postFilePath + "\\" + biz + "\\" + post+ "\\" + post + ".html"));
String content_Str = new String(bytes);
content_Str = replaceTextOfMatchGroup(content_Str, picsrcPattern, 0, srcStr -> {
int index = srcStr.indexOf("=");
String picUrl = srcStr.substring(index + 2, srcStr.length() - 1);
//将src中的图片链接替换成本地图片链接
srcStr = srcStr.replaceAll("(?<=src\\=\\\").*(?=\\\")", String.format("/index/weixin/postImg/%s/%s/%s/", biz, post, picUrl));
return srcStr;
});
HttpSession session = request.getSession();
ServletContext sc = session.getServletContext();
String path = sc.getRealPath("/");
ResourceLoader resourceLoader = new DefaultResourceLoader();
Resource resource = resourceLoader.getResource("file:" + path + "/WEB-INF/view/article.html");
//将本地文件写到article中
FileOutputStream outputStreamWriter = new FileOutputStream(resource.getFile());
outputStreamWriter.write(content_Str.getBytes());
ModelAndView modelAndView = new ModelAndView("post");
return modelAndView;
}项目中的日志有两种记录方式,一种是用logback记录的,这种是记录运行时的日志,另一种是将爬取的错误信息记录到数据库中。
- 爬虫日志
爬虫日志是直接输出到控制台上的,这其中是用到了Spring aop做日志的输出。
项目中的aop主要是用LoggerAspect去实现日志的输出,用LogAfter和LogBefore两个注解类去做方法的aop,从爬取的开始到结束都会输出相关的日志。
- 错误日志
错误日志是在try-catch中做处理的,所以只有在try-catch中捕获的错误信息才会被记录到Mysql中。而没有被捕获的信息和直接外抛的异常都不会被记录到Mysql中,而是直接输出到控制台上,所以对于一些突发的运行时错误会有错误定位的问题。
目前已实现的功能
- 爬取历史公众号历史文章
- 爬取公众号最新文章
- 本地文章查看
- 按文章标题和内容搜索文章
待优化和增加的功能
- 优化历史文章爬取速度
- 优化更新新文章的流程
- 优化搜素结果
- 实现爬取可配置